In building out some functionality for WPLauncher, we needed to pull the PHP versions from php.net/releases. In order to do this, we didn’t want to go through the page and copy each of the over 100 PHP versions, we’re developers after all! So, we put together a super simple website scraping script using jQuery and the Chrome console. There are three easy steps to creating a simple website scraping script.
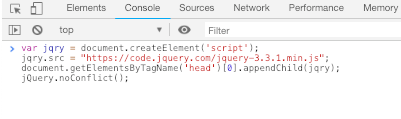
Step 1: Load jQuery in the Chrome Console
You could use JavaScript out of the box in creating a scraping script for a website but jQuery seemed like it would take less time
We have a post that outlines the easiest way to do this. Check it out at https://blog.wplauncher.com/run-jquery-in-chrome-console/. You’ll want to click on the Console tab and then paste the code from that post into the console.
Step 2: Check out the HTML Elements on the Page You Want to Scrape
So, we wanted to get all of the versions from php.net/releases. Go to that page in Google Chrome and inspect the page. You do this by right clicking on your mouse on an element on the page and clicking on Inspect.
Make sure you are on the Elements tab. This will show the HTML elements that make up the page, i.e. the HTML structure of the page.

Step 3: Create Your Scraping Script
From the structure shown in the image above, I could see that each h2 child element within the layout-content section (the section element with an id equal to layout-content), held the versions that I needed to pull from the page. I wanted to compile a full list of PHP versions. So, I looped through all h2 children within the layout-children element and I concatenated them together within the versions variable. The versions were displayed throughout the loop, but most importantly, the full list of versions was visible at the end of the loop.
loadPHPVersions();
function loadPHPVersions(){
var versions = '';
$('#layout-content').children('h2').each(function(){
var $thisParent = $(this);
versions += $thisParent.text() + ',';
console.log(versions);
});
}You obviously will need to modify the above script to fit whatever page you want to scrape. A good background in
User-agent: *
Disallow: /backend/
Disallow: /distributions/
Disallow: /stats/
Disallow: /server-status/
Disallow: /search.php
Disallow: /mod.php
Disallow: /manual/add-note.php
Disallow: /manual/vote-note.php
Disallow: /harming/humans
Disallow: /ignoring/human/orders
Disallow: /harm/to/self